








Patrick Farnan is a software engineering manager at Signifyd working in our research and development hub in Belfast, to help deliver quick, reliable and rich data to our customers and internal staff for reporting and performance analysis. Patrick shares his insights on working with big data and cloud computing, and the ever-changing landscape of technologies used to allow for fast and complex processing. Patrick worked with his team to help create better data transfer hygiene and more robust reporting to stay on the cutting edge of our organization’s tech stack needs.
Welcome to the challenge!
When I joined the Signifyd Belfast engineering as a team lead in April, I started working on one of the teams that manages Signifyd’s data and satisfies our reporting requirements for internal and external customers. My biggest project so far was to rethink and redesign how we move data from one store to another, and to hone the most efficient way of utilizing it.
One of the biggest challenges for Signifyd is how we handle and store the ever-growing amount of data that moves through our systems. We now handle millions of transactions daily from thousands of global customers, which provides opportunities for significant insights into patterns and behaviors and challenges in how to best manage this volume efficiently and intelligently.
The Initial Setup
Over the past few years, we’ve revisited the technology stack used throughout our system, including our data storage technologies and transportation between them. Like many software companies, we have leveraged a myriad of tools and storage mechanisms to meet our internal and external needs. This introduces issues with maintenance and updates to varying systems, as well as potential inconsistencies appearing in the data available or the “freshness” in replicated stores. As Signifyd matures, so has a lot of the infrastructure and toolsets available, especially in cloud computing and data management.
In one of the earliest examples of transporting data from primary to secondary stores, we moved our core transactional data from a Cassandra data storage and replicated it to Redshift instances within our Amazon Web Services (AWS) cloud-based infrastructure for analytical and reporting purposes. The initial implementation used a mix of AWS specific technologies to quickly spin up an Extract-Load-Transformation (ETL) pipeline.
There were a few missteps along the way. We tried writing record IDs to files for querying (not the most efficient approach!), then later settled on a solution of using Kinesis Firehose to consume events triggered by data changes and track these for transfer later. By storing the specific references to the records updated, we were able to move off the previous approach. This approach involved running queries using a component called Solr which had to search across all records for those updated or created within a given time period. As our database got bigger this query took longer to run and return values.
Once we did that, we used AWS Data Pipeline by manually coupling several pipelines to perform the Extract, Transformation and Loading elements required for a given period on a recurring schedule, like new or update transactions over the course of a 15 minute window.
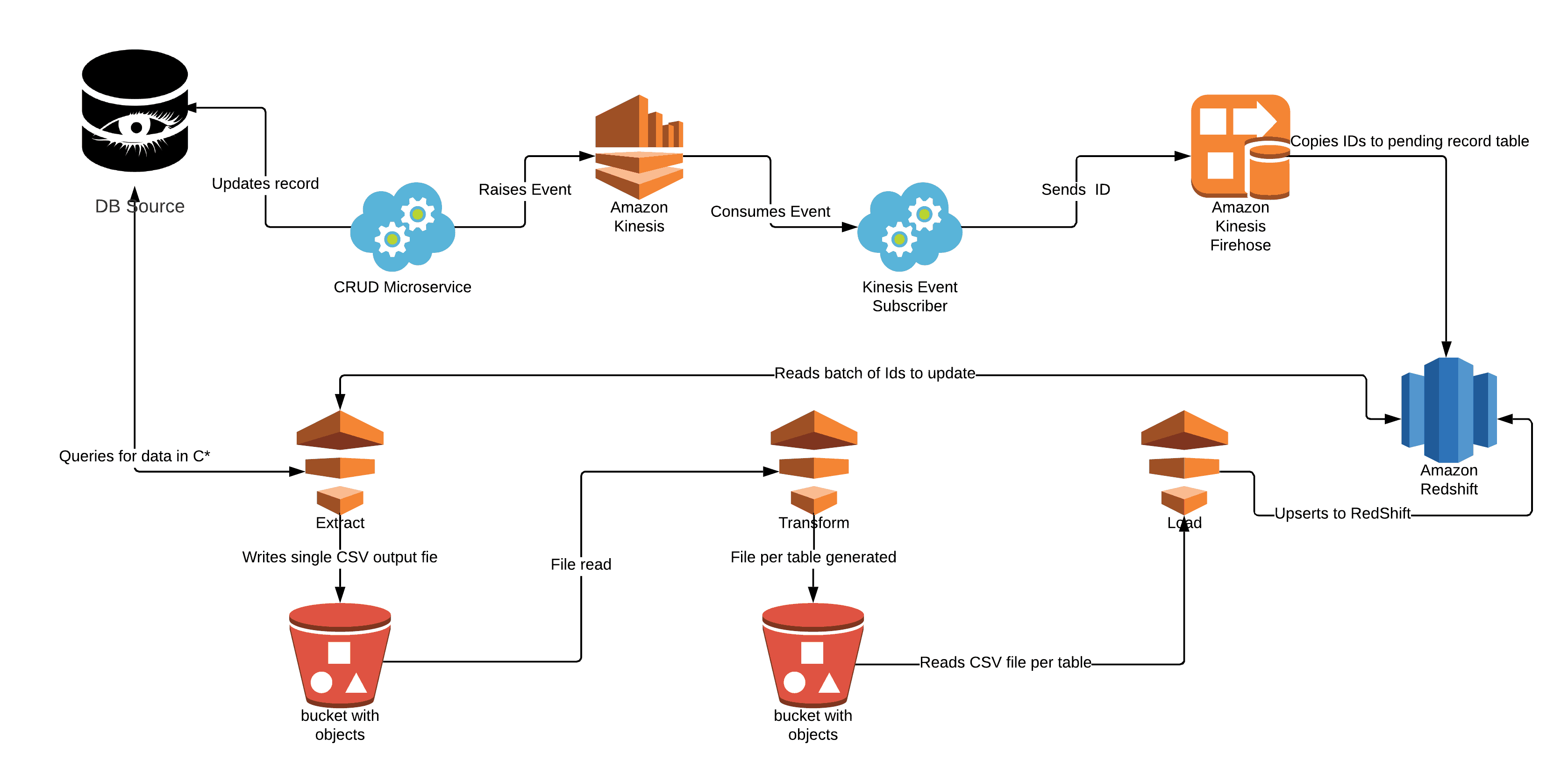
This diagram illustrates our Data Pipeline Process
Time to rethink
This approach worked well enough to allow the data to flow through, but over time, and as Signifyd’s customer base grew, the amount of records that were being created or updated over the 15 minute window increased drastically. The upturn in data processed caused the three stages to take longer and longer to complete, to the point at which a single execution of the ETL took more than 15 minutes causing increased delays in data delivery. As a consequence of this we split out these pipelines further to throttle how often certain parts of data were copied across. But all this workaround did was to cause further unwanted lag, increase the need for maintenance and create a growing problem as we became more successful.
Our initial solution talked directly to our primary data store to obtain the latest record state. This data store is a NoSql database called Apache Cassandra, which allows for the fast retrieval and writing of data, and can handle vast quantities of records in a reliable fashion. However by our ETLs transferring ever-increasing volumes of records in each 15-minute window, we also increased the amount of additional requests being made against Cassandra to pull out the current record state for each. As Cassandra is a mission critical part of the Signifyd infrastructure, and leveraged by other systems which require it for more important operations, the increased traffic caused unnecessary performance impacts and used up resources that could otherwise be used elsewhere. The increased data transfer flow was also prone to failure, due to the delicate binding together of the pieces involved. It caused major issues like Firehose writing data for updates, or activities in the pipelines failing at various points with minimal logging or error tracing.
Recovering such failures grew more cumbersome over time, and more susceptibilities appeared. The nature of the setup made building a new AMI (Amazon Machine Image — essentially the information needed to create a new instance of a virtual server) to resolve such problems more painful for the team.
Plus, the original approach only served a single data store, Redshift. As our data engineers sought to interrogate our data further for patterns and signs of risk, they only had two options:
- Use the current Redshift clusters setup, which was already under a significant load and also not the most efficient tool for their purposes
- Write their own pipeline to pull data from Cassandra to another store
My team chose the latter, where we created a new additional ETL which used a different technology to load and write the data out. The data was written out in formatted files into S3 (Simple Storage Service), which is essentially a file storage solution offered and managed by AWS. It caters for large objects or files to be stored and retrieved quickly, with security and reliability built in. The data in these files were then queried and accessed by a combination of
Apache Spark (more on that later!) and Hive Tables, which is an open source data warehouse system to help analyze large datasets.
The way forward
The inconsistencies in the approaches above, how data was stored and the effort replication, led to a concerted effort to design and develop an infrastructure that was more efficient, resilient and standardized. It crucially also allowed other use cases or teams to access the data without requiring a rework or reimplementation. By reusing some of our existing components and building on top of them, we were able to come up with a solution that catered to our needs.
The first approach was to define a standard version of our underlying data model that could be interpreted by all our datastores to help unify the team’s understanding and reduce potential inconsistencies. Then, we split the process for how we transferred data from our primary store to other stores, and added a single Spark application to consume and use the events raised from data changes to write the underlying records to an offline store in S3 using Spark and Hudi for faster updates. These records are stored in the previously defined canonical format. As we write these updates to S3 we maintain a ledger of changes for other applications to use later when consuming.
Once in this offline store (sometimes called a Data Lake), the data can be accessed directly over S3. For the initial implementation of transferring this data to Redshift, another Spark application inspects the ledger and pulls a number of updates to be written in batches. This helps throttle the data writing during peak periods. The application uses the same underlying format for interpreting and writing the data to a new Redshift schema which matches this offline structure. It also inspects the current schema as persisted in Redshift and maps to the canonical format to reduce any code changes as new or existing record definitions alter. With the data read and interpreted, it is then loaded into staging tables within Redshift for temporary storage. For example: for customer information we might store it in a staging table called customers_staging. This table would mirror the destination tables structure but contain only the records for the current execution. When the data is in the staging table it is then written to the target table, for example customers, by performing either an update to an existing record with the same ID, or insert a new record (this is also known as up-serting).
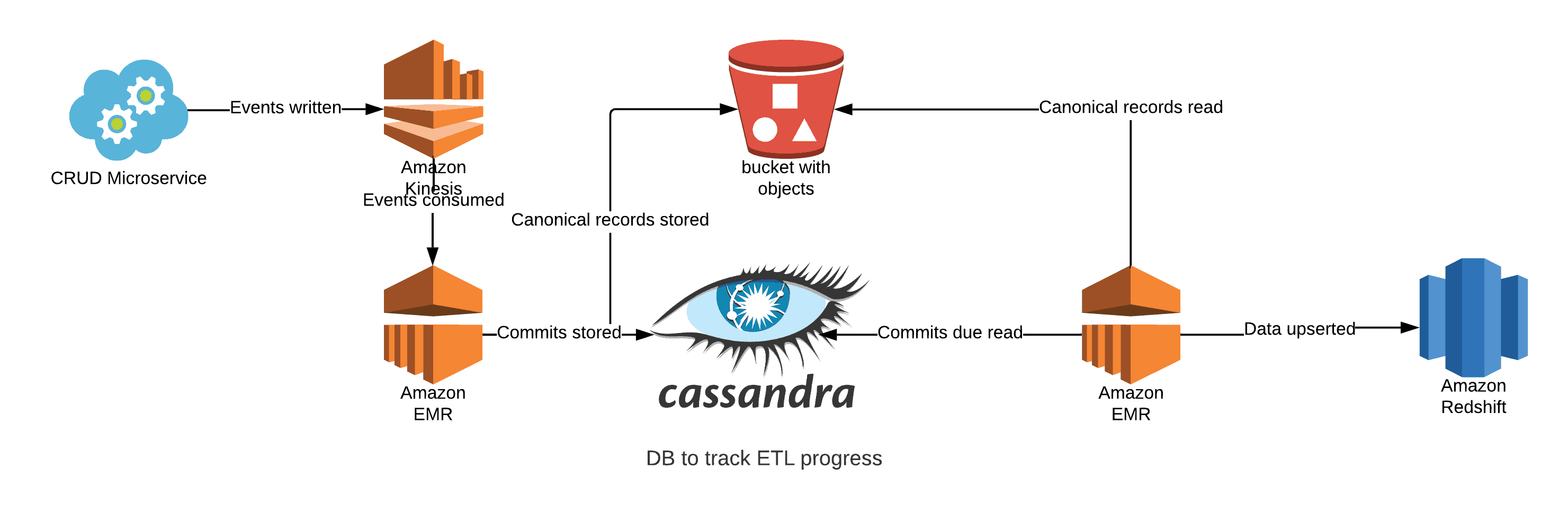
This diagram illustrates our Spark ETL Process
As part of the above process, we replaced a large amount of the ETL processing with Spark applications running in Amazon EMR (Elastic MapReduce) – this is a cloud based platform built to process vast amounts of data quickly and cost-effectively. We leveraged Spark for this process for a number of reasons:
- Speed of processing data: The engine is around 100 times faster in memory during execution, by reducing disk read/writes and leveraging in-memory computation.
- Ease of use: Spark comes with a rich set of APIs and operators for transforming and working on data, especially in large amounts.
- A unified engine: Spark supports a large number of operations, from SQL queries, data streaming, machine learning and graph processing. We can boost productivity by combining complex workflows.
- Multiple language support: We can use key languages including Scala, R, Java and Python with this tool.
- Community spirit: We’re part of the expanding Spark community, a group that contributes to the framework’s underlying source code to add features or fix bugs, as well as help develop related frameworks and toolkits.
Future work
Completing this initial piece has allowed the Signifyd engineering teams to plan for enhancing our reporting. One area for future development is transitioning our reporting using Redshift as the primary offline data store. We currently maintain a full history of data with Redshift, which is largely unused for records older than a couple of years — a detriment that increases data size and cost and can reduce query performance.
Our enhancements provide a standard format for our records and allow us to use other technologies such as Redshift Spectrum to expose certain data from our S3 store rather than explicitly Redshift. This will reduce database size (and costs) and improve performance for most of our use cases which focus on more recent data.
It also allows our teams to maintain entire history access for our internal and external customers. We are also looking at running these Spark applications within our own Kubernetes clusters rather than Amazon EMR. This will make testing and development much easier, and reduce dependency on another component for execution.
The ability to work on emerging and modern technology stacks, and focus on solving real problems for our customers, makes my job a challenging and rewarding learning experience every day. Technology and our customers never stand still, so neither can we!
Signifyd is hiring for key engineering and data science positions. For more information about our open positions and what it’s like working at Signifyd, check out our Careers page.
